Fuzzing API endpoints
With the help of JS Recon Tool, you can generate a list of endpoints to fuzz. Along with that, it also generates a list of potential hosts that can be used to fuzz the API endpoints.
This is an offline process; however, it requires the JS files to be downloaded.
Tools required
- JS Recon
- Any web fuzzer
- GUI
- Web proxied like Burp Suite or Caido
- CLI
- GUI
- An API Client
Downloading the JS files
The lazyload module can be used to download all the lazy-loaded, that is, dynamically loaded, JavaScript files.
To do so, you can run the following command. The docs for lazyload module can be referred here to understand the command:
js-recon lazyload -u <url_or_file>
Upon running the following command, it will give the following output:
❯ tree
.
└── output
└── <domain>
├── _next
│ ├── data
│ │ └── k7xKVnxmboK4SktY2dZWt
│ │ └── index.json
│ └── static
│ ├── chunks
│ │ ├── 12.7e6d2ac6e1808fc2.js
│ │ ├── framework-64ad27b21261a9ce.js
│ │ ├── main-710ab85aa9a8f10d.js
│ │ ├── pages
│ │ │ ├── _app-c449865c8af1faa0.js
│ │ │ ├── _error-77823ddac6993d35.js
│ │ │ ├── -af5a23529ce3c337.js
│ │ │ └── 5D-af5a23529ce3c337.js
│ │ ├── polyfills-78c92fac7aa8fdd8.js
│ │ └── webpack-efff35ee26971294.js
│ └── k7xKVnxmboK4SktY2dZWt
│ ├── _buildManifest.js
│ └── _ssgManifest.js
└── cdn-cgi
└── scripts
└── 5c5dd728
└── cloudflare-static
└── email-decode.min.js
The output directory contains all the JS files that are extracted from the site. This file can be further passed to other sub-commands for offline analysis, or can also be manually analyzed, which is demonstrated in the next guide.
Using the string module to extract all the endpoints
The next step is to extract all the strings, along with endpoints. The target can be fuzzed right away; however, it is recommended to use the lazyload module to also fetch the subsequent requests. The demonstration and the reason for the same can be found here
Once you've downloaded all the JS files, you can run the strings command to extract all the API endpoints.
js-recon strings -d output/<target_domain> -e
The strings module iterates through all the JS files in the specified directory, and extracts all the strings. Since the -e flag is enabled, it will then iterate through all the strings found, match them against the known patterns of URLs and paths, and generate the extracted_urls.json file (unless changed by passing the flag)
The following is the structure of the extracted_urls.json:
{
"urls": [
"https://api.example.com",
"https://rum.example.com",
"https://www.example.com",
"https://app.example.com",
"https://internal.app.com"
],
"paths": [
"/v1/admin",
"/v1/dashboard",
"/v1/members",
"/v1/report",
"/v1/settings",
"/v1/edit"
]
}
To permutate the URLs and the paths found, you add the -p flag in the previous command:
js-recon strings -d output/<target_domain> -e
This will generate a new text file called extracted_urls.txt, which contains the full URLs. Following is a hypothetical example of the same:
https://app.example.com/app/v1/admin/something0
https://app.example.com/app/v1/admin/something1
https://app.example.com/app/v1/admin/something2
https://app.example.com/app/v1/admin/something3
https://app.example.com/app/v1/admin/something4
https://app.example.com/app/v1/admin/something5
https://app.example.com/app/v1/admin/something6
https://app.example.com/app/v1/admin/something7
https://app.example.com/app/v1/admin/something8
https://app.example.com/app/v1/admin/something9
A lot of this would be 404 Not Found; however, it will also contain the valid endpoints.
The endpoints in the generated text file could be either client-side or server-side endpoints.
Client-Side Endpoints: These are rendered on the user's browser. Often, the server returns the same response to these endpoints, and whether the endpoint is valid or not is determined when rendered on browsers.
Server-Side Endpoints: These are the endpoints for which the server is expected to perform an action, which is often an API for the service. The content type for this endpoint is often JSON (which is popular in the REST API context)
Fuzzing
Using ffuf
The API endpoints are the most interesting when analyzing the requests of an app. These perform some action, and often, when the server doesn't use server-side rendering, all the possible endpoints for the app could be potentially found in the files the lazyload downloaded.
You can weaponize this feature of the application. To do so, you can use tools like ffuf or any other fuzzer that you use.
The absolute URLs generated by this module are stored in the extracted_urls.txt file. We can directly feed this in ffuf with the following command:
ffuf -u FUZZ -w extracted_urls.txt
This will print everything, including garbage. To filter down the results, you can filter based on the status code, which is the first thing that you would like to do. For this, you can use the -fc (filter code) flag in ffuf and filter the 404 Not Found URLs:
ffuf -u FUZZ -w extracted_urls.txt -fc 404
Since we are fuzzing for API, you would also like to filter based on the content type for JSON. Since an option for this isn't directly available in ffuf, you can use the proxy of your choice.
Since I use Caido, here's a filter for the same.
resp.raw.cont:"Content-Type: application/json"
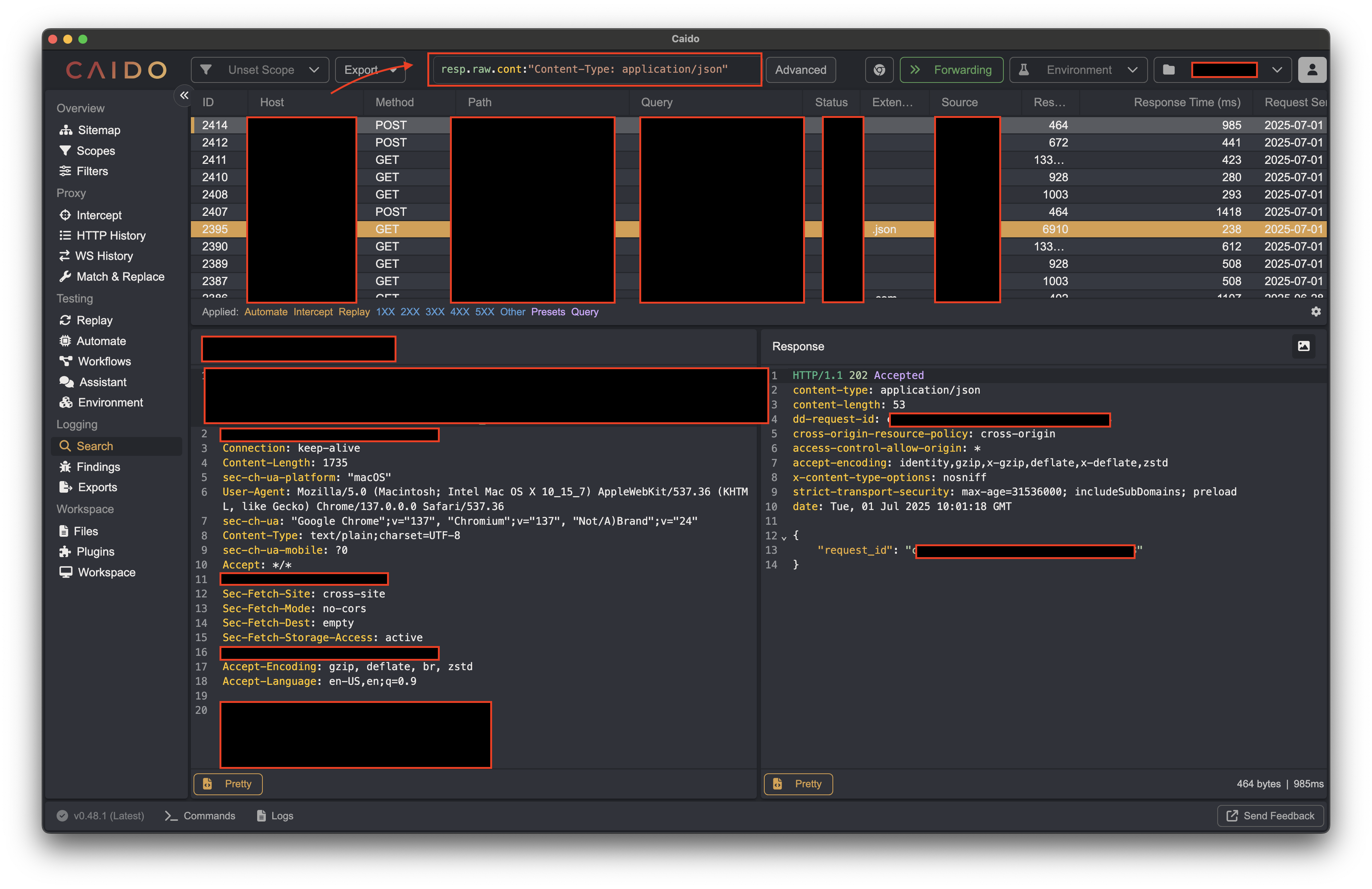
Even though the above image is heavily redacted, it gives an overview of the filter.
Using an API client
You can also create an API collection for the paths found, and then use the 'Run API Collection' feature of the API client to fuzz the endpoint. This could be a more convenient method of fuzzing if your primary target is APIs
To do so, you can run the following command:
js-recon strings -d <output_dir> -e --openapi
This will generate a new file extracted_urls-openapi.json, which is the standard OpenAPI v3 collection. This means that this can be used with most of the API clients. Since my preferred API client is Bruno, here's a screenshot for a hypothetical application:
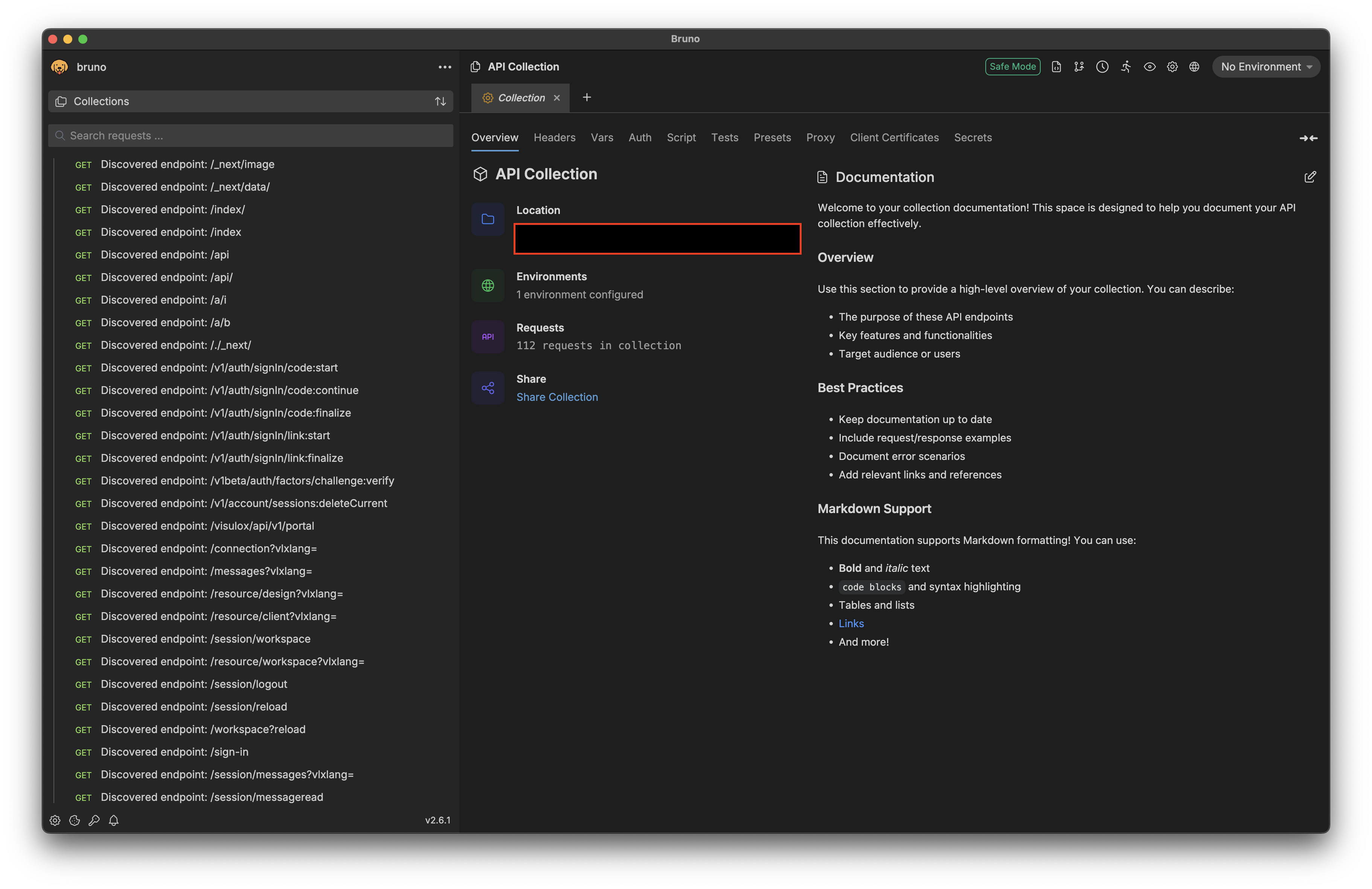
In the above example, you can observe that the collection contains several endpoints, some of which appear to be API paths, and other seems to be client-side paths.
This route could be noisy, but could land you at quick bugs without having to deep-dive into all the JS files.